- sex 31 maio 2019
- datasets
- Álvaro Justen
- #python, #data science
Muitos datasets que possuem dados sobre pessoas não possuem a informação de gênero correspondente, como o dataset de candidatura das eleições para o ano de 1.996 divulgado pelo Tribunal Superior Eleitoral (veja esse dataset no Brasil.IO) e o dataset de salários dos magistrados divulgado pelo Conselho Nacional de Justiça (veja esse dataset no Brasil.IO). A falta dessa informação dificulta projetos de dados onde o recorte por gênero é necessário, como é o caso desse vídeo que ajudei a construir, onde classificamos por gênero todos os nomes de ruas, avenidas e praças do Brasil.
Nesse artigo vamos aprender a utilizar os dados de nomes brasileiros do Censo 2010 do IBGE que estão disponíveis no Brasil.IO para fazer essa classificação, utilizando como base mais de 100 mil nomes e a linguagem Python! :)
Instalando as dependências¶
Antes de iniciar o código criaremos um ambiente virtual (virtualenv) utilizando a versão 3.7 do Python (vou utilizar o pyenv e pyenv-virtualenv para isso, mas fique à vontade para utilizar outras ferramentas em seu ambiente). Para esse projeto utilizaremos apenas as bibliotecas da standard library do Python, ou seja, não precisaremos instalar bibliotecas externas.
pyenv virtualenv 3.7.3 classificador-genero
pyenv activate classificador-genero
Entendendo o Dataset¶
A tabela nomes do dataset genero-nomes possui a lista de todos os nomes encontrados no Censo 2010, contendo a frequência desse nome para os gêneros masculino e feminino, a classificação baseada nessa frequência (o gênero que tiver frequência maior) e a probabilidade da classificação ser verdadeira (frequência do gênero que aparece mais dividida pela frequência total do nome), como podemos ver na seguinte tabela:
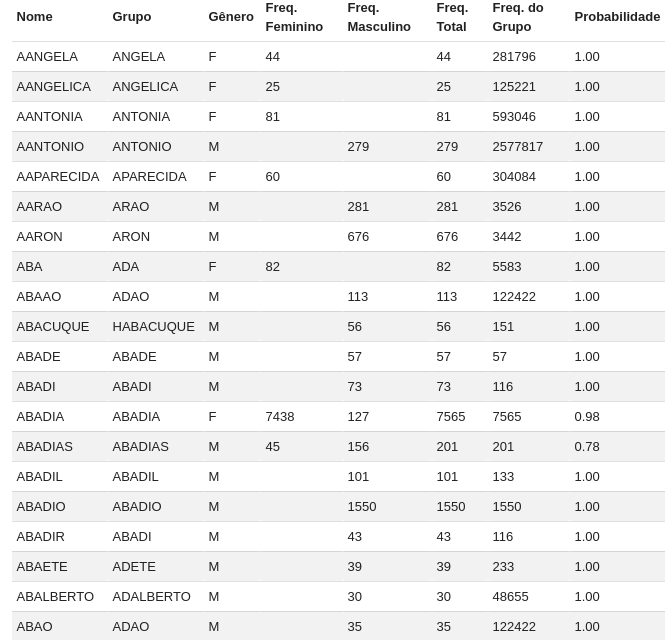
Para o nome ABADIAS, por exemplo, existem 45 pessoas do gênero feminimo e 156 do masculino, então o nome é classificado com o gênero M (masculino) com uma probabilidade de 78% (156 / (156 + 45)).
Repare também que os nomes contidos nesse dataset estão todos em letras maiúsculas e sem acentos, então precisaremos criar uma função para transformar o nome que queremos classificar (exemplo: Álvaro) para esse formato. Para isso, vamos utilizar a função normalize do módulo unicodedata para separar os acentos das letras e ignorar os erros ao converter para o encoding ASCII, que eliminará todos os símbolos que não queremos:
from unicodedata import normalize
def encode(name):
ascii_name = normalize("NFKD", name).encode("ascii", errors="ignore").decode("ascii")
return ascii_name.upper()
print(encode("Álvaro"))
Possíveis Abordagens¶
Para esse projeto vamos fazer um classificador simples, sem a utilização de técnicas de aprendizado de máquina, ou seja, ele será capaz de classificar apenas os nomes já disponíveis em nosso dataset. Em próximos artigos mostraremos como criar outros tipos de classificadores.
Para resolver essa questão, temos duas abordagens possíveis:
- Utilizar a API do Brasil.IO, fazendo uma requisição a cada nome a ser classificado; e
- Baixar o dataset completo e utilizar os dados localmente.
Cada uma das abordagens tem vantagens e desvantagens, que veremos a seguir.
Método 1: Utilizando a API¶
Vantagens:
- Não precisaremos baixar o dataset completo
- Utiliza pouca memória
Desvantagens:
- Classificação lenta (uma requisição HTTP por classificação)
Vamos criar uma função que recebe o nome, faz a requisição HTTP usando a urllib, lê os dados com a json e retorna o resultado encontrado:
import json
from urllib.request import urlopen
def classify_api(name):
encoded_name = encode(name)
url = "https://brasil.io/api/dataset/genero-nomes/nomes/data?first_name=" + encoded_name
response = urlopen(url)
json_response = json.loads(response.read())
return json_response["results"][0]["classification"]
print(classify_api("Álvaro"))
Fica como sugestão de exercício melhorar a função acima, adicionando tratamento de erros caso o nome não seja encontrado.
Método 2: Baixando os dados¶
Vantagens:
- Classificação rápida (acesso à chave de um dicionário)
Desvantagens:
- Precisaremos baixar o dataset completo
- Utiliza mais memória
Vamos utilizar o wget no terminal para baixar a tabela nomes completa:
wget https://data.brasil.io/dataset/genero-nomes/nomes.csv.gz
Agora, vamos ler o arquivo CSV e criar um dicionário em que cada chave será um nome e o valor será a classificação correspondente, para isso utilizaremos os módulos gzip (para descompactar o arquivo), io (para decodificar o conteúdo do arquivo descompactado) e csv (para ler o arquivo).
import csv
import gzip
import io
def load_data():
fobj = io.TextIOWrapper(gzip.open("nomes.csv.gz"), encoding="utf-8")
csv_reader = csv.DictReader(fobj)
data = {
row["first_name"]: row["classification"]
for row in csv_reader
}
fobj.close()
return data
name_data = load_data()
print(f"Dicionário criado com {len(name_data)} nomes.")
Com a variável name_data definida podemos criar a função de classificação facilmente:
def classify_download(name):
encoded_name = encode(name)
return name_data[encoded_name]
print(classify_download("Álvaro"))
Comparando as Soluções¶
A primeira solução não exige tempo de download inicial, nem de carragamento dos dados, porém é bem mais lenta - cada classificação demora em torno de 1 segundo (esse valor pode variar, dependendo de sua conexão à Internet e à carga nos servidores do Brasil.IO):
%timeit classify_api("Álvaro")
Já a segunda solução requer o download (uma única vez) de um arquivo de 1,9MB e mais um tempo inicial de quase meio segundo para carregar os dados em memória, porém é 1 milhão de vezes mais rápida - cada classificação demora em torno de 1 microssegundo (esse valor pode variar dependendo do processador e velocidades do disco e da memória):
%timeit load_data()
%timeit classify_download("Álvaro")
Conclusão¶
Podemos utilizar dados públicos para enriquecer diversos outros datasets, possibilitando análises que antes não seriam possíveis. A utilização da API do Brasil.IO é bem simples e pode ser útil em casos de poucas consultas, mas quando a quantidade de consultas aumenta, o ideal é baixar os dados e trabalhar com eles localmente.
Curtiu o artigo? Se você acha o trabalho que desenvolvemos importante, considere fazer uma doação ou colaborar de outras formas. ;)
